ClickHouse原理解析与应用实践
第一章 ClickHouse的前世今生
OLAP 常见架构分类
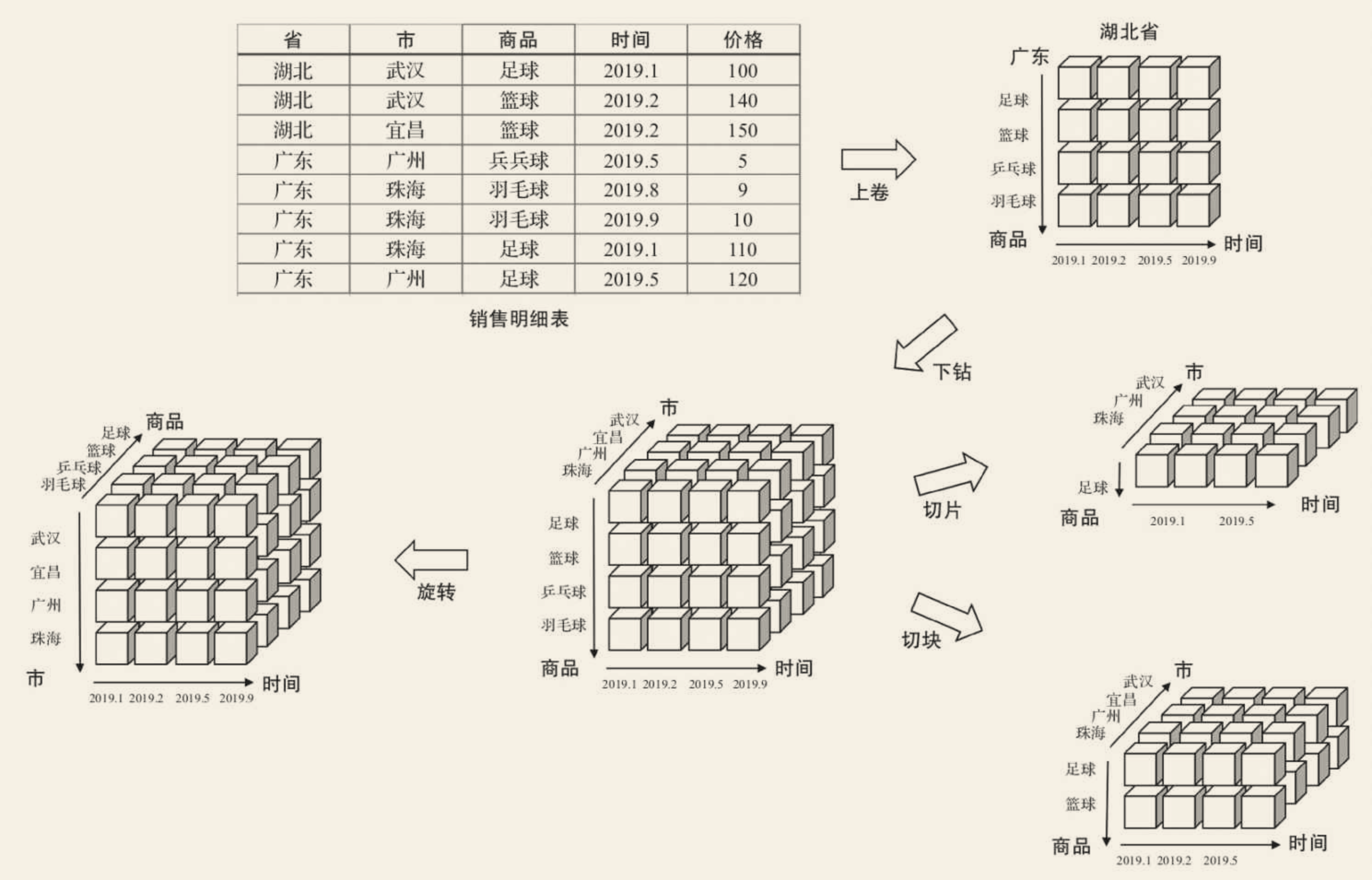
多维数据分析常见操作
- 下钻: 从高层次向低层次明细数据穿透。例如从“省”下钻到“市”,从“湖北省”穿透到“武汉”和“宜昌”。
- 上卷: 和下钻相反,从低层次向高层次汇聚。例如从“市”汇聚成“省”,将“武汉”“宜昌”汇聚成“湖北”。
- 切片: 观察立方体的一层,将一个或多个维度设为单个固定值,然后观察剩余的维度,例如将商品维度固定为“足球”。
- 切块: 与切片类似,只是将单个固定值变成多个值。例如将商品维度固定成“足球”“篮球”和“乒乓球”。
- 旋转: 旋转立方体的一面,如果要将数据映射到一张二维表,那么就要进行旋转,这就等同于行列置换。”
架构分类
- ROLAP(Relational OLAP,关系型OLAP)
- MOLAP(Multidimensional OLAP,多维型OLAP)
- HOLAP(Hybrid OLAP,混合架构的OLAP)
相关资料
第九章 数据查询
WITH 子句
定义
ClickHouse支持CTE(Common Table Expression,公共表表达式),以增强查询语句的表达
Syntax
1
2
3
| WITH <expression> AS <identifier>
-- or
WITH <identifier> AS <subquery expression>
|
场景一:定义变量
1
2
3
4
5
6
7
8
| WITH 10 AS start
SELECT
number
FROM
system.numbers
WHERE
number > start
limit 10
|
场景二:调用函数
1
2
3
4
5
6
7
8
9
10
| WITH SUM(data_uncompressed_bytes) AS bytes
SELECT
database ,
formatReadableSize(bytes) AS format
FROM
system.columns
GROUP BY
database
ORDER BY
bytes DESC
|
- 把
bytes 函数定义成公共表达式供其他 SQL 使用
场景三:定义子查询
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
| /* this example would return TOP 10 of most huge tables */
WITH (
SELECT
sum(bytes)
FROM
system.parts WHEREactive) AS total_disk_usage
SELECT
(sum(bytes) / total_disk_usage) * 100 AS table_disk_usage,
table
FROM
system.parts
GROUP BY
table
ORDER BY
table_disk_usage DESC
LIMIT 10;
|
场景四:在子查询中重复使用 WITH
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
| -- 在计算出各database未压缩数据大小与数据总和的比例之后,又进行了取整函数的调用
WITH (
round(database_disk_usage)
) AS database_disk_usage_v1
SELECT
database,
database_disk_usage,
database_disk_usage_v1
FROM
(
WITH (
SELECT
SUM(data_uncompressed_bytes)
FROM
system.columns
) AS total_bytes
SELECT
database ,
(SUM(data_uncompressed_bytes) / total_bytes) * 100 AS database_disk_usage
FROM
system.columns
GROUP BY
database
ORDER BY
database_disk_usage DESC
)
|
From 子句
从数据表中取数
从子查询中取数
从表函数中取数
1
| SELECT number FROM numbers(5)
|
SAMPLE 子句
概念/场景
SAMPLE子句能够实现数据采样的功能,使查询仅返回采样数据而不是全部数据,从而有效减少查询负载
这种采样机制是幂等的。如果数据没有发生变化,使用相同的采样规则总是能够返回相同的数据。这个特性适合在需要高效查询而不要求绝对准确性的场景使用。要求在 CREATE TABLE 时声明 SAMPLE BY 抽样表达式。
查询语法
| SAMPLE Clause Syntax | 产品描述 |
|---|
SAMPLE k | 这里 k 是从0到1的数字。 查询执行于 k 数据的分数。 例如, SAMPLE 0.1 对10%的数据运行查询。 Read more |
SAMPLE n | 这里 n 是足够大的整数。 该查询是在至少一个样本上执行的 n 行(但不超过这个)。 例如, SAMPLE 10000000 在至少10,000,000行上运行查询。 Read more |
SAMPLE k OFFSET m | 这里 k 和 m 是从0到1的数字。 查询在以下示例上执行 k 数据的分数。 用于采样的数据由以下偏移 m 分数。 Read more |
SAMPLE factor
- 在进行统计查询时,为了得到最终的近似结果,需要将得到的直接结果乘以采样系数。例如若想按0.1的因子采样数据,则需要将统计结果放大10倍
1
| SELECT count() * 10 FROM hits_v1 SAMPLE 0.1
|
SAMPLE rows
- SAMPLE rows表示按样本数量采样,其中rows表示至少采样多少行数据,它的取值必须是大于1的整数。如果rows的取值大于表内数据的总行数,则效果等于rows=1(即不使用采样)
SAMPLE factor OFFSET n
- SAMPLE factor OFFSET n 表示按因子系数和偏移量采样,其中factor表示采样因子,n表示偏移多少数据后才开始采样,它们两个的取值都是0~1之间的小数。
1
2
| SELECT CounterID FROM hits_v1 SAMPLE 0.4 OFFSET 0.5
-- 查询会从数据的二分之一处开始,按 0.4 的系数采样数据
|
ARRAY JOIN 子句
ARRAY JOIN子句允许在数据表的内部,与数组或嵌套类型的字段进行JOIN操作,从而将一行数组展开为多行
INNER ARRAY JOIN
ARRAY JOIN 在默认情况下使用的是 INNER JOIN 策略
1
2
3
4
5
6
7
8
9
| SELECT title,value,v FROM query_v1 ARRAY JOIN value AS v
┌─title─┬─value──┬─v─┐
│ food │ [1,2,3] │ 1 │
│ food │ [1,2,3] │ 2 │
│ food │ [1,2,3] │ 3 │
│ fruit │ [3,4] │ 3 │
│ fruit │ [3,4] │ 4 │
└─────┴──────┴───┘
-- 数组被展开成了多行,并且排除掉了空数组
|
LEFT ARRAY JOIN
普通查询和合并查询
1
2
3
4
5
6
7
8
9
10
| SELECT title,value,v FROM query_v1 LEFT ARRAY JOIN value AS v
┌─title─┬─value──┬─v─┐
│ food │ [1,2,3] │ 1 │
│ food │ [1,2,3] │ 2 │
│ food │ [1,2,3] │ 3 │
│ fruit │ [3,4] │ 3 │
│ fruit │ [3,4] │ 4 │
│ meat │ [] │ 0 │
└─────┴──────┴──┘
-- 在 INNER JOIN 中被排除掉的空数组出现在了返回的结果集中
|
1
2
3
4
5
6
7
8
9
10
11
|
SELECT title,value,v ,arrayMap(x -> x * 2,value) as mapv,v_1 FROM query_v1 LEFT ARRAY JOIN value AS v , mapv as v_1
┌─title─┬─value──┬─v─┬─mapv───┬─v_1─┐
│ food │ [1,2,3] │ 1 │ [2,4,6] │ 2 │
│ food │ [1,2,3] │ 2 │ [2,4,6] │ 4 │
│ food │ [1,2,3] │ 3 │ [2,4,6] │ 6 │
│ fruit │ [3,4] │ 3 │ [6,8] │ 6 │
│ fruit │ [3,4] │ 4 │ [6,8] │ 8 │
│ meat │ [] │ 0 │ [] │ 0 │
└─────┴──────┴───┴──────┴────┘
-- ARRAY JOIN多个数组时,是合并,不是笛卡儿积
|
嵌套类型数组
嵌套数据对齐限制
1
2
3
4
5
6
7
8
| INSERT INTO query_v2 VALUES ('food', [1,2,3], [10,20,30]), ('fruit', [4,5], [40,50]), ('meat', [], [])
SELECT title, nest.v1, nest.v2 FROM query_v2
┌─title─┬─nest.v1─┬─nest.v2───┐
│ food │ [1,2,3] │ [10,20,30] │
│ fruit │ [4,5] │ [40,50] │
│ meat │ [] │ [] │
└─────┴──────┴────────┘
-- 同一行数据,数组长度要对齐
|
访问方式
对嵌套类型数据的访问,ARRAY JOIN既可以直接使用字段列名
1
2
3
4
| SELECT title, nest.v1, nest.v2 FROM query_v2 ARRAY JOIN nest
-- 字段列名访问
SELECT title, nest.v1, nest.v2 FROM query_v2 ARRAY JOIN nest.v1, nest.v2
-- 点访问符
|
ARRAY JOIN部分嵌套
1
2
3
4
5
6
7
8
9
|
SELECT title, nest.v1, nest.v2 FROM query_v2 ARRAY JOIN nest.v1
┌─title─┬─nest.v1─┬─nest.v2───┐
│ food │ 1 │ [10,20,30] │
│ food │ 2 │ [10,20,30] │
│ food │ 3 │ [10,20,30] │
│ fruit │ 4 │ [40,50] │
│ fruit │ 5 │ [40,50] │
-- 也可以只ARRAY JOIN其中部分字段
|
JOIN 子句
graph LR
A[ALL/ANY/ASOF\n连接精度] -- + --> B["LEFT/RIGHT/FULL[OUTER]\n外连接"]
A -- + --> C[INNER\n内连接]
A -- + --> D[CROSS\n交叉连接]
B --> E[JOIN]
C --> E[JOIN]
D --> E[JOIN]
连接精度分为 **ALL、ANY 和 ASOF **三种,而连接类型也可分为外连接、内连接和交叉连接三种
测试表
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
| -- join_tb1
┌─id─┬─name──────┬─────────time─┐
│ 1 │ ClickHouse │ 2019-05-01 12:00:00 │
│ 2 │ Spark │ 2019-05-01 12:30:00 │
│ 3 │ ElasticSearch │ 2019-05-01 13:00:00 │
│ 4 │ HBase │ 2019-05-01 13:30:00 │
│ NULL │ ClickHouse │ 2019-05-01 12:00:00 │
│ NULL │ Spark │ 2019-05-01 12:30:00 │
└────┴─────────┴─────────────┘
-- join_tb2
┌─id─┬─rate─┬─────────time─┐
│ 1 │ 100 │ 2019-05-01 11:55:00 │
│ 2 │ 90 │ 2019-05-01 12:01:00 │
│ 3 │ 80 │ 2019-05-01 13:10:00 │
│ 5 │ 70 │ 2019-05-01 14:00:00 │
│ 6 │ 60 │ 2019-05-01 13:50:00 │
└───┴────┴─────────────┘
-- join_tb3
┌─id─┬─star─┐
│ 1 │ 1000 │
│ 2 │ 900 │
└───┴────┘
|
连接精度
ALL
如果左表内的一行数据,在右表中有多行数据与之连接匹配,则返回右表中全部连接的数据
1
2
3
4
5
6
7
8
9
| SELECT a.id,a.name,b.rate FROM join_tb1 AS a
ALL INNER JOIN join_tb2 AS b ON a.id = b.id
┌─id─┬─name──────┬─rate──┐
│ 1 │ ClickHouse │ 100 │
│ 1 │ ClickHouse │ 105 │
│ 2 │ Spark │ 90 │
│ 3 │ ElasticSearch │ 80 │
└───┴─────────┴──────┘
-- 结果集返回了右表中所有与左表id相匹配的数据
|
ANY
如果左表内的一行数据,在右表中有多行数据与之连接匹配,则仅返回右表中第一行连接的数据
1
2
3
4
5
6
7
8
9
| SELECT a.id,a.name,b.rate FROM join_tb1 AS a
ANY INNER JOIN join_tb2 AS b ON a.id = b.id
┌─id─┬─name──────┬─rate──┐
│ 1 │ ClickHouse │ 100 │
│ 2 │ Spark │ 90 │
│ 3 │ ElasticSearch │ 80 │
└───┴─────────┴──────┘
-- 结果集仅返回了右表中与左表id相连接的第一行数据
|
ASOF
ASOF是一种模糊连接,它允许在连接键之后追加定义一个模糊连接的匹配条件 asof_column
1
2
3
4
5
6
7
8
9
| SELECT a.id,a.name,b.rate,a.time,b.time
FROM join_tb1 AS a ASOF INNER JOIN join_tb2 AS b
ON a.id = b.id AND a.time >= b.time
┌─id─┬─name────┬─rate─┬────time──────┬──────b.time───┐
│ 1 │ ClickHouse │ 100 │ 2019-05-01 12:00:00 │ 2019-05-01 11:55:00 │
│ 2 │ Spark │ 90 │ 2019-05-01 12:30:00 │ 2019-05-01 12:01:00 │
└───┴───────┴────┴─────────────┴─────────────┘
-- 其最终返回的查询结果符合连接条件a.id=b.id AND a.time>=b.time,且仅返回了右表中第一行连接匹配的数据
|
ASOF支持使用USING的简写形式,USING后声明的最后一个字段会被自动转换成asof_colum模糊连接条件
1
2
3
| SELECT a.id,a.name,b.rate,a.time,b.time FROM join_tb1 AS a ASOF
INNER JOIN join_tb2 AS b USING(id,time)
-- USING后的time字段会被转换成asof_colum,跟上面 SQL 同样效果
|
对于asof_colum字段的使用有两点需要注意:
- asof_colum必须是整型、浮点型和日期型这类有序序列的数据类型
- asof_colum不能是数据表内的唯一字段,换言之,连接键(JOIN KEY)和asof_colum不能是同一个字段
连接类型
连接类型决定了JOIN查询组合左右两个数据集合要用的策略,它们所形成的结果是交集、并集、笛卡儿积或是其他形式
INNER
只会返回左表与右表两个数据集合中交集的部分,其余部分都会被排除
OUTER
1
2
| [LEFT|RIGHT|FULL [OUTER]] ] JOIN
-- 其中,OUTER修饰符可以省略
|
LEFT
在进行左外连接查询时,会以左表为基础逐行遍历数据,然后从右表中找出与左边连接的行以补齐属性。如果在右表中没有找到连接的行,则采用相应字段数据类型的默认值填充
1
2
3
4
5
6
7
8
9
10
11
| SELECT a.id,a.name,b.rate FROM join_tb1 AS a
LEFT OUTER JOIN join_tb2 AS b ON a.id = b.id
┌─id──┬─name──────┬─rate──┐
│ 1 │ ClickHouse │ 100 │
│ 1 │ ClickHouse │ 105 │
│ 2 │ Spark │ 90 │
│ 3 │ ElasticSearch │ 80 │
│ 4 │ HBase │ 0 │
└────┴─────────┴──────┘
-- 左表join_tb1内的数据全部返回,其中id为4的数据在右表中没有连接,所以由默认值0补全
|
RIGHT
右外连接查询的效果与左连接恰好相反,右表的数据总是能够全部返回,而左表不能连接的数据则使用默认值补全
1
2
3
4
5
6
7
8
9
10
| SELECT a.id,a.name,b.rate FROM join_tb1 AS a
RIGHT JOIN join_tb2 AS b ON a.id = b.id
┌─id──┬─name──────┬─rate──┐
│ 1 │ ClickHouse │ 100 │
│ 1 │ ClickHouse │ 105 │
│ 2 │ Spark │ 90 │
│ 3 │ ElasticSearch │ 80 │
│ 5 │ │ 70 │
│ 6 │ │ 60 │
└────┴─────────┴──────┘
|
FULL
全外连接查询会返回左表与右表两个数据集合的并集
1
2
3
4
5
6
7
8
9
10
11
| SELECT a.id,a.name,b.rate FROM join_tb1 AS a
FULL JOIN join_tb2 AS b ON a.id = b.id
┌─id──┬─name──────┬─rate──┐
│ 1 │ ClickHouse │ 100 │
│ 1 │ ClickHouse │ 105 │
│ 2 │ Spark │ 90 │
│ 3 │ ElasticSearch │ 80 │
│ 4 │ HBase │ 0 │
│ 5 │ │ 70 │
│ 6 │ │ 60 │
└────┴─────────┴──────┘
|
CROSS
CROSS JOIN表示交叉连接,它会返回左表与右表两个数据集合的笛卡儿积。也正因为如此,CROSS JOIN不需要声明JOIN KEY,因为结果会包含它们的所有组合
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
| “SELECT a.id,a.name,b.rate FROM join_tb1 AS a
CROSS JOIN join_tb2 AS b
┌─id──┬─name──────┬─rate──┐
│ 1 │ ClickHouse │ 100 │
│ 1 │ ClickHouse │ 105 │
│ 1 │ ClickHouse │ 90 │
│ 1 │ ClickHouse │ 80 │
│ 1 │ ClickHouse │ 70 │
│ 1 │ ClickHouse │ 60 │
│ 2 │ Spark │ 100 │
│ 2 │ Spark │ 105 │
│ 2 │ Spark │ 90 │
│ 2 │ Spark │ 80 │
...
-- 在进行交叉连接查询时,会以左表为基础,逐行与右表全集相乘
|
多表连接
在进行多张数据表的连接查询时,ClickHouse会将它们转为两两连接的形式
1
2
3
4
5
6
7
8
9
10
| SELECT a.id,a.name,b.rate,c.star FROM join_tb1 AS a
INNER JOIN join_tb2 AS b ON a.id = b.id
LEFT JOIN join_tb3 AS c ON a.id = c.id
┌─a.id─┬─a.name────┬─b.rate──┬─c.star──┐
│ 1 │ ClickHouse │ 100 │ 1000 │
│ 1 │ ClickHouse │ 105 │ 1000 │
│ 2 │ Spark │ 90 │ 900 │
│ 3 │ ElasticSearch │ 80 │ 0 │
└─────┴─────────┴───────┴───────┘
-- 先将join_tb1与join_tb2进行内连接,之后再将它们的结果集与join_tb3左连接
|
注意事项
- 为了能够优化JOIN查询性能,首先应该遵循左大右小的原则,即将数据量小的表放在右侧。这是因为在执行JOIN查询时,无论使用的是哪种连接方式,右表都会被全部加载到内存中与左表进行比较
- 如果是在大量维度属性补全的查询场景中,则建议使用字典代替JOIN查询
- 连接查询的空值策略是通过 join_use_nulls 参数指定的,默认为0。当参数值为0时,空值由数据类型的默认值填充;而当参数值为1时,空值由Null填充
- JOIN KEY支持简化写法,当数据表的连接字段名称相同时,可以使用 USING 语法简写
1
2
3
4
| SELECT a.id,a.name,b.rate FROM join_tb1 AS a
INNER JOIN join_tb2 AS b ON a.id = b.id
-- USING简写
SELECT id,name,rate FROM join_tb1 INNER JOIN join_tb2 USING id
|
WHERE 与 PREWHERE 子句
WHERE 子句基于条件表达式来实现数据过滤。如果过滤条件恰好是主键字段,则能够进一步借助索引加速查询,所以 WHERE 子句是一条查询语句能否启用索引的判断依据(前提是表引擎支持索引特性)
PREWHERE 目前只能用于 MergeTree 系列的表引擎。使用 PREWHERE 时,首先只会读取 PREWHERE 指定的列字段数据,用于数据过滤的条件判断。待数据过滤之后再读取 SELECT 声明的列字段以补全其余属性。
GROUP BY 子句
1
2
3
4
| SELECT SUM(data_compressed_bytes) AS compressed ,
SUM(data_uncompressed_bytes) AS uncompressed
FROM system.parts
-- SELECT 后只声明了聚合函数,则可以省略 GROUP BY 关键字
|
1
2
3
4
| -- 除了聚合函数外,只能使用聚合 key 中包含的 table 字段
SELECT table,COUNT() FROM system.parts GROUP BY table
-- 使用聚合 key 中未声明的 rows 字段,则会报错
SELECT table,COUNT(),rows FROM system.parts GROUP BY table
|
可以借助 any、max 和 min 等聚合函数访问聚合键之外的列字段
1
2
3
4
5
6
| SELECT table,COUNT(),any(rows) FROM system.parts GROUP BY table
┌─table────┬─COUNT()─┬─any(rows)─┐
│ partition_v1 │ 1 │ 4 │
│ agg_merge2 │ 1 │ 1 │
│ hits_v1 │ 2 │ 8873898 │
└────────┴───────┴────────┘
|
当聚合查询内的数据存在NULL值时,ClickHouse会将 NULL 作为 NULL=NULL 的特定值处理
1
2
3
4
5
6
7
8
| SELECT arrayJoin([1, 2, 3,null,null,null]) AS v GROUP BY v
┌───v───┐
│ 1 │
│ 2 │
│ 3 │
│ NULL │
└───────┘
-- NULL值都被聚合到了NULL分组
|
WITH ROLLUP
ROLLUP能够按照聚合键从右向左上卷数据,基于聚合函数依次生成分组小计和总计。如果设聚合键的个数为n,则最终会生成小计的个数为n+1。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
| SELECT table, name, SUM(bytes_on_disk) FROM system.parts
GROUP BY table,name
WITH ROLLUP
ORDER BY table
┌─table──────┬─name──────┬─SUM(bytes_on_disk)─┐
│ │ │ 2938852157 │
│partition_v1 │ │ 670 │
│ partition_v1 │ 201906_6_6_0 │ 160 │
│ partition_v1 │ 201905_1_3_1 │ 175 │
│ partition_v1 │ 201905_5_5_0 │ 160 │
│ partition_v1 │ 201906_2_4_1 │ 175 │
│query_v4 │ │ 459 │
│ query_v4 │ 201906_2_2_0 │ 203 │
│ query_v4 │ 201905_1_1_0 │ 256 │
省略…
└─────────┴─────────┴─────────────┘
|
WITH CUBE
CUBE会像立方体模型一样,基于聚合键之间所有的组合生成小计信息。如果设聚合键的个数为n,则最终小计组合的个数为2的n次方
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
| SELECT database, table, name, SUM(bytes_on_disk) FROM
(SELECT database, table, name, bytes_on_disk FROM system.parts WHERE table ='hits_v1')
GROUP BY database,table,name
WITH CUBE
ORDER BY database,table ,name
┌─database─┬─table──┬─name──────┬─SUM(bytes_on_disk) ──┐
│ │ │ │ 1460381504 │
│ │ │ 201403_1_29_2 │ 1271367153 │
│ │ │ 201403_1_6_1 │ 189014351 │
│ │ hits_v1 │ │ 1460381504 │
│ │ hits_v1 │ 201403_1_29_2 │ 1271367153 │
│ │ hits_v1 │ 201403_1_6_1 │ 189014351 │
│ datasets │ │ │ 1271367153 │
│ datasets │ │ 201403_1_29_2 │ 1271367153 │
│ datasets │ hits_v1 │ │ 1271367153 │
│ datasets │ hits_v1 │ 201403_1_29_2 │ 1271367153 │
│ default │ │ │ 189014351 │
│ default │ │ 201403_1_6_1 │ 189014351 │
│ default │ hits_v1 │ │ 189014351 │
│ default │ hits_v1 │ 201403_1_6_1 │ 189014351 │
└───────┴──────┴─────────┴──────────────┘
|
WITH TOTALS
使用TOTALS修饰符后,会基于聚合函数对所有数据进行总计
1
2
3
4
5
6
7
8
9
10
11
12
| SELECT database, SUM(bytes_on_disk),COUNT(table) FROM system.parts
GROUP BY database WITH TOTALS
┌─database─┬─SUM(bytes_on_disk)─┬─COUNT(table)─┐
│ default │ 378059851 │ 46 │
│ datasets │ 2542748913 │ 3 │
│ system │ 152144 │ 3 │
└───────┴─────────────┴─────────┘
Totals:
┌─database─┬─SUM(bytes_on_disk)─┬─COUNT(table)─┐
│ │ 2920960908 │ 52 │
└───────┴─────────────┴─────────┘
-- 其结果附加了一行Totals汇总合计,这一结果是基于聚合函数对所有数据聚合总计的结果
|
HAVING子句
HAVING子句需要与GROUP BY同时出现,不能单独使用。它能够在聚合计算之后实现二次过滤数据
1
2
3
4
5
6
7
| SELECT table ,avg(bytes_on_disk) as avg_bytes
FROM system.parts GROUP BY table
HAVING avg_bytes > 10000
┌─table─────┬───avg_bytes───┐
│ hits_v1 │ 730190752 │
└─────────┴────────────┘
-- 因为WHERE的执行优先级大于GROUP BY,所以如果需要按照聚合值进行过滤,就必须借助HAVING实现
|
ORDER BY子句
如果在查询时数据跨越了多个分区,则它们的返回顺序是无法预知的,每一次查询返回的顺序都可能不同。在这种情形下,如果需要数据总是能够按照期望的顺序返回,就需要借助ORDER BY子句来指定全局顺序
如果在查询时数据跨越了多个分区,则它们的返回顺序是无法预知的,每一次查询返回的顺序都可能不同。在这种情形下,如果需要数据总是能够按照期望的顺序返回,就需要借助ORDER BY子句来指定全局顺序
1
2
3
4
5
6
| SELECT arrayJoin([1,2,3]) as v1 , arrayJoin([4,5,6]) as v2
ORDER BY v1 ASC, v2 DESC
SELECT arrayJoin([1,2,3]) as v1 , arrayJoin([4,5,6]) as v2
ORDER BY v1, v2 DESC
-- 按照v1升序、v2降序排序, 默认为ASC(升序)
|
NULLS 策略
NULLS LAST
1
2
3
4
5
6
7
8
9
10
11
12
13
14
| WITH arrayJoin([30,null,60.5,0/0,1/0,-1/0,30,null,0/0]) AS v1
SELECT v1 ORDER BY v1 DESC NULLS LAST
┌───v1─┐
│ inf │
│ 60.5 │
│ 30 │
│ 30 │
│ -inf │
│ nan │
│ nan │
│ NULL │
│ NULL │
└─────┘
-- 顺序是value -> NaN -> NULL
|
NULLS FIRST
1
2
3
4
5
6
7
8
9
10
11
12
13
14
| WITH arrayJoin([30,null,60.5,0/0,1/0,-1/0,30,null,0/0]) AS v1
SELECT v1 ORDER BY v1 DESC NULLS FIRST
┌──v1─┐
│ NULL │
│ NULL │
│ nan │
│ nan │
│ inf │
│ 60.5 │
│ 30 │
│ 30 │
│ -inf │
└────┘
-- 顺序是NULL -> NaN -> value
|
LIMIT BY 子句
运行于ORDER BY之后和LIMIT之前,能够按照指定分组,最多返回前n行数据(如果数据少于n行,则按实际数量返回),常用于TOP N的查询场景
语法:LIMIT n BY express
1
2
3
4
5
6
7
8
9
10
11
12
13
14
|
SELECT database,table,MAX(bytes_on_disk) AS bytes FROM system.parts
GROUP BY database,table ORDER BY database ,bytes DESC
LIMIT 3 BY database
┌─database─┬─table───────┬───bytes──┐
│ datasets │ hits_v1 │ 1271367153 │
│ datasets │ hits_v1_1 │ 1269636153 │
│ default │ hits_v1_1 │ 189025442 │
│ default │ hits_v1 │ 189014351 │
│ default │ partition_v5 │ 5344 │
│ system │ query_log │ 81127 │
│ system │ query_thread_log │ 68838 │
└───────┴───────────┴────────┘
-- limit n by,查询返回数据占磁盘空间最大的前3张表
|
声明多个表达式需使用逗号分隔,例如下面的语句能够得到每张数据表所定义的字段中,使用最频繁的前5种数据类型
1
2
3
| SELECT database,table,type,COUNT(name) AS col_count FROM system.columns
GROUP BY database,table,type ORDER BY col_count DESC
LIMIT 5 BY database,table
|
LIMIT BY也支持跳过OFFSET偏移量获取数据
1
2
3
| LIMIT n OFFSET y BY express
-- 简写
LIMIT y,n BY express
|
LIMIT子句
LIMIT子句用于返回指定的前n行数据,常用于分页场景,它的三种语法形式如下所示
1
2
3
| LIMIT n
LIMIT n OFFSET m
LIMIT m,n
|
LIMIT子句可以和LIMIT BY一同使用
1
2
3
4
5
| SELECT database,table,MAX(bytes_on_disk) AS bytes FROM system.parts
GROUP BY database,table ORDER BY bytes DESC
LIMIT 3 BY database
LIMIT 10
-- 查询返回数据占磁盘空间最大的前3张表,而返回的总数据行等于10
|
注意⚠️:在使用LIMIT子句时有一点需要注意,如果数据跨越了多个分区,在没有使用ORDER BY指定全局顺序的情况下,每次LIMIT查询所返回的数据有可能不同。如果对数据的返回顺序敏感,则应搭配ORDER BY一同使用
SELECT子句
如果使用 * 通配符,则会返回数据表的所有字段。对于一款列式存储的数据库而言,这是劣势而不是优势
在选择列字段时,ClickHouse还为特定场景提供了一种基于正则查询的形式
1
2
3
4
5
6
| SELECT COLUMNS('^n'), COLUMNS('p') FROM system.databases
┌─name────┬─data_path────┬─metadata_path───┐
│ default │ /data/default/ │ /metadata/default/ │
│ system │ /data/system/ │ /metadata/system/ │
└───────┴──────────┴────────────┘
-- 查询会返回名称以字母 n 开头和包含字母 p 的列字段
|
DISTINCT子句
DISTINCT子句能够去除重复数据
当DISTINCT与ORDER BY同时使用时,其执行的优先级是先DISTINCT后ORDER BY
1
2
3
4
5
6
7
8
| SELECT DISTINCT name FROM query_v5 ORDER BY v1 ASC
┌─name─┐
│ a │
│ c │
│ b │
│ NULL │
│ d │
└─────┘
|
UNION ALL子句
UNION ALL子句能够联合左右两边的两组子查询,将结果一并返回。在一次查询中,可以声明多次UNION ALL以便联合多组查询,但UNION ALL不能直接使用其他子句(例如ORDER BY、LIMIT等),这些子句只能在它联合的子查询中使用
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
| CREATE TABLE union_v1
(
name String,
v1 UInt8
) ENGINE = Log
INSERT INTO union_v1 VALUES('apple',1),('cherry',2),('banana',3)
CREATE TABLE union_v2
(
title Nullable(String),
v1 Float32
) ENGINE = Log
INSERT INTO union_v2 VALUES('apple',20),
(null,4.5),('orange',1.1),('pear',2.0),('lemon',3.54)
-- 测试数据
SELECT name,v1 FROM union_v1
UNION ALL
SELECT title,v1 FROM union_v2
-- 联合查询
|
有几个特点:
- 列字段的数量必须相同
- 列字段的数据类型必须相同或相兼容
- 列字段的名称可以不同,查询结果中的列名会以左边的子查询为准
目前ClickHouse只支持UNION ALL子句,如果想得到UNION DISTINCT子句的效果,可以使用嵌套查询来变相实现
1
2
3
4
5
6
| SELECT DISTINCT name FROM
(
SELECT name,v1 FROM union_v1
UNION ALL
SELECT title,v1 FROM union_v2
)
|
查看SQL执行计划
ClickHouse目前并没有直接提供EXPLAIN查询,但是借助后台的服务日志,能变相实现该功能
1
| clickhouse-client -h ch7.nauu.com --send_logs_level=trace <<< 'SELECT * FROM hits_v1' > /dev/null
|
假设数据表hits_v1的关键属性如下所示
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
| CREATE TABLE hits_v1 (
WatchID UInt64,
EventDate DATE,
CounterID UInt32,
...
)ENGINE = MergeTree()
PARTITION BY toYYYYMM(EventDate)
ORDER BY CounterID
SETTINGS index_granularity = 8192
-- 表属性
SELECT COUNT(*) FROM hits_v1
┌─COUNT()─┐
│ 8873910 │
└──────┘
-- 分区键是EventDate,主键是CounterID。在写入测试数据后,这张表的数据约900万行
SELECT partition_id ,name FROM 'system'.parts WHERE 'table' = 'hits_v1' AND active = 1
┌─partition_id┬─name──────┐
│ 201403 │ 201403_1_7_1 │
│ 201403 │ 201403_8_13_1 │
│ 201403 │ 201403_14_19_1 │
│ 201403 │ 201403_20_25_1 │
│ 201403 │ 201403_26_26_0 │
│ 201403 │ 201403_27_27_0 │
│ 201403 │ 201403_28_28_0 │
│ 201403 │ 201403_29_29_0 │
│ 201403 │ 201403_30_30_0 │
│ 201405 │ 201405_31_40_2 │
│ 201405 │ 201405_41_41_0 │
│ 201406 │ 201406_42_42_0 │
└────────┴─────────┘
-- 测试数据还拥有12个分区
|
全字段、全表扫描
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
| [root@ch7 ~]# clickhouse-client -h ch7.nauu.com --send_logs_level=trace <<< 'SELECT * FROM hits_v1' > /dev/null
[ch7.nauu.com] 2020.03.24 21:17:18.197960 {910ebccd-6af9-4a3e-82f4-d2291686e319} [ 45 ] <Debug> executeQuery: (from 10.37.129.15:47198) SELECT * FROM hits_v1
[ch7.nauu.com] 2020.03.24 21:17:18.200324 {910ebccd-6af9-4a3e-82f4-d2291686e319} [ 45 ] <Debug> default.hits_v1 (SelectExecutor): Key condition: unknown
[ch7.nauu.com] 2020.03.24 21:17:18.200350 {910ebccd-6af9-4a3e-82f4-d2291686e319} [ 45 ] <Debug> default.hits_v1 (SelectExecutor): MinMax index condition: unknown
[ch7.nauu.com] 2020.03.24 21:17:18.200453 {910ebccd-6af9-4a3e-82f4-d2291686e319} [ 45 ] <Debug> default.hits_v1 (SelectExecutor): Selected 12 parts by date, 12 parts by key, 1098 marks to read from 12 ranges
[ch7.nauu.com] 2020.03.24 21:17:18.205865 {910ebccd-6af9-4a3e-82f4-d2291686e319} [ 45 ] <Trace> default.hits_v1 (SelectExecutor): Reading approx. 8917216 rows with 2 streams
[ch7.nauu.com] 2020.03.24 21:17:18.206333 {910ebccd-6af9-4a3e-82f4-d2291686e319} [ 45 ] <Trace> InterpreterSelectQuery: FetchColumns -> Complete
[ch7.nauu.com] 2020.03.24 21:17:18.207143 {910ebccd-6af9-4a3e-82f4-d2291686e319} [ 45 ] <Debug> executeQuery: Query pipeline:
Union
Expression × 2
Expression
MergeTreeThread
[ch7.nauu.com] 2020.03.24 21:17:46.460028 {910ebccd-6af9-4a3e-82f4-d2291686e319} [ 45 ] <Trace> UnionBlockInputStream: Waiting for threads to finish
[ch7.nauu.com] 2020.03.24 21:17:46.463029 {910ebccd-6af9-4a3e-82f4-d2291686e319} [ 45 ] <Trace> UnionBlockInputStream: Waited for threads to finish[…]
|
分析该 SQL 执行计划
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
| Union
Expression × 2
Expression
MergeTreeThread
# 使用了2个线程执行,并最终通过Union合并了结果集
Key condition: unknown
# 没有使用主键索引
MinMax index condition: unknown
# 没有使用分区索引
Selected 12 parts by date, 12 parts by key, 1098 marks to read from 12 ranges
# 该查询语句共扫描了12个分区目录,共计1098个MarkRange
Read 8873910 rows, 8.50 GiB in 28.267 sec., 313928 rows/sec., 308.01 MiB/sec.
# 该查询语句总共读取了8 873 910行数据(全表),共8.50 GB
MemoryTracker: Peak memory usage (for query): 340.03 MiB.
# 该查询语句消耗内存最大时为340 MB
|
单个字段、全表扫描
1
2
3
4
5
6
7
8
| clickhouse-client -h ch7.nauu.com --send_logs_level=trace <<< 'SELECT WatchID FROM hits_v1' > /dev/null
# 执行该查询语句
Read 8873910 rows, 67.70 MiB in 0.195 sec., 45505217 rows/sec., 347.18 MiB/sec.
# 会发现该查询语句仍然会扫描所有的12个分区,并读取8873910行数据,但结果集大小由之前的8.50 GB降低到了现在的67.70 MB
MemoryTracker: Peak memory usage (for query): 17.56 MiB.
# 内存的峰值消耗也从先前的340 MB降低为现在的17.56 MB
|
使用分区索引
1
2
3
4
5
6
7
8
9
10
11
12
13
14
| clickhouse-client -h ch7.nauu.com --send_logs_level=trace <<< "SELECT WatchID FROM hits_v1 WHERE EventDate = '2014-03-17'" > /dev/null
# 执行该查询语句, 增加WHERE子句,并将分区字段EventDate作为查询条件
InterpreterSelectQuery: MergeTreeWhereOptimizer: condition "EventDate = '2014-03-17'" moved to PREWHERE
# WHERE子句被自动优化成了PREWHERE子句
MinMax index condition: (column 0 in [16146, 16146])
# 分区索引被启动了
Selected 9 parts by date, 9 parts by key, 1095 marks to read from 9 ranges
# 借助分区索引,这次查询只需要扫描9个分区目录,剪枝了3个分区
Reading approx. 8892640 rows with 2 streams
# 由于仍然没有启用主键索引,所以该查询仍然需要扫描9个分区内,即所有的1095个MarkRange。所以,最终需要读取到内存的预估数据量为8892640行
|
使用主键索引
继续修改SQL语句,在WHERE子句中增加主键字段CounterID的过滤条件
1
2
| SELECT WatchID FROM hits_v1 WHERE EventDate = '2014-03-17'
AND CounterID = 67141
|
1
2
3
4
5
6
7
8
9
10
11
| clickhouse-client -h ch7.nauu.com --send_logs_level=trace <<< "SELECT WatchID FROM hits_v1 WHERE EventDate = '2014-03-17' AND CounterID = 67141 " > /dev/null
# 执行该查询语句
Key condition: (column 0 in [67141, 67141])
# 上次的基础上主键索引也被启动了
Selected 9 parts by date, 8 parts by key, 8 marks to read from 8 ranges
# 由于启用了主键索引,所以需要扫描的MarkRange由1095个降到了8个
Reading approx. 65536 rows with 2 streams
# 现在最终需要读取到内存的预估数据量只有65536行(8192*8)
|
总结
- 通过将 ClickHouse 服务日志设置到 DEBUG 或者 TRACE 级别,可以变相实现 EXPLAIN 查询,以分析 SQL 的执行日志
- 需要真正执行了 SQL 查询,CH 才能打印计划日志,所以如果表的数据量很大,最好借助 LIMIT 子句以减小查询返回的数据量
- 在日志中,分区过滤信息部分如下所示:
Selected xxx parts by date。其中 by date 是固定的,无论我们的分区键是什么字段,这里都不会变。这是由于在早期版本中,MergeTree 分区键只支持日期字段 - 不要使用
SELECT * 全字段查询 - 尽可能利用各种索引(分区索引、一级索引、二级索引),这样可避免全表扫描